谁说大象不能跳舞:基于Java的Markdown预览插件
Java一直以来都给人留下了笨重的印象,按说插件这种轻量的任务根本和Java没啥关系,但是这次我要霸王硬上弓,让大象跳次舞。
跳什么舞呢?这是个问题,突然想起写博客一直困扰自己的一个问题:我一直使用Vim编写Markdown,有时候难免想看看效果,欣赏下文字跳动的样子,但是Vim不支持预览,自己一直用Chrome一款插件Markdown Viewer进行预览,遗憾的是这款插件不支持动态刷新也不支持同步滚动,所以如果你没有一下点出十个信号的手速,这个操作是比较尴尬的。既然这样,能不能用Java整个插件呢?
整体思路
既然现在Markdown Viewer只能显示不能滚动,那么通过程序将Vim的某种位置信息传给浏览器,然后调用js滚动到这个位置不就可以了吗?想让浏览器显示网页而且网页的内容还得不停的变,需要一个Web服务器,这正是Java的强项。从浏览器到Java的路走通了,但是Vim到Java的路怎么走呢?由于Vim不支持Java,二者怎么通信呢,这时看到著名的胶水语言,编程语言界的媒婆Python是被Vim支持的,方案有了:让Python与Java通信。好,这样整个流程就通了。整体框架如下所示:
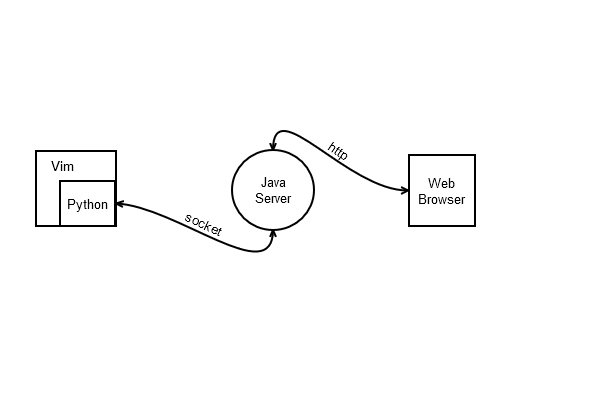
Java服务器
Web这片领域简直就是Java的主场,自然一点问题没有。以前学过Netty,一直没有派上用场,这次终于可以小试牛刀了。
public class HttpRequestHandler extends SimpleChannelInboundHandler<FullHttpRequest> {
private MarkDownServer server;
public HttpRequestHandler(MarkDownServer server) {
this.server = server;
}
@Override
public void channelRead0(ChannelHandlerContext ctx, FullHttpRequest request) {
String uri = request.uri();
if (uri.startsWith("/index")) {
index(ctx, request);
} else if (uri.startsWith("/ws")) {
ctx.fireChannelRead(request.retain());
} else if (uri.startsWith("/js") || uri.startsWith("/css")) {
transferStaticFile(ctx, request);
} else if (uri.startsWith("/image")) {
image(ctx, request);
} else {
commonResponse(ctx, request, FileUtils.getBytes("How do you do"), MiMeType.PLAIN);
}
}
}
上面即是Web服务的框架程序,细节就不贴了。但是有几个问题大家要注意:
- 服务器怎么和浏览器通信?
- 网页里的js和css怎么返回?
- Python怎么和Java通信?
上面的程序处理的正是前两个问题。
先说服务器怎么和浏览器通信,最初定的是ajax,但是后来找到一种更好的方案WebSocket,WebSocket可以让浏览器和服务器保持长连接,有更好的流畅性和速度,这就是上面/ws所处理的内容。
第二个问题,网页中的静态文件js和css需要让服务器返回,就像tomcat这些通用服务器做的那样,这里没什么复杂的,就是一个简单的文件读写,只有一点需要注意:文件的编码,否则页面会乱码。
第三个问题,Python怎么和Java通信,最初采用的是py4j,优点是这个库可以直接在Python里调用Java程序,缺点是需要安装额外的库,对于有着代码洁癖的我不是一个完美的方案,后来一想既然已经有了Web服务器,直接使用Http不就可以了,所以将方案又改为使用Http与Java通信,经过实验,这个方案虽然不用安装额外的库了,但是由于Python的原装urllib库不能保持长连接,随着连接的增多,速度会慢慢降下来,看来还得另寻出路。
private class SocketServerHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf in = (ByteBuf) msg;
String string = in.toString(CharsetUtil.UTF_8);
LOGGER.info("Server received: " + string);
String[] data = string.split(SEP);
switch (data[0]) {
case "start":
server = MarkDownServer.getInstance();
server.setTheme(data[2]);
server.start(Integer.parseInt(data[1]));
break;
case "sync":
server.broadcast("sync", data[1], Base64Utils.decode2String(data[2]), Integer.parseInt(data[3]));
break;
case "close":
server.broadcast("close", data[1], "", 1);
break;
case "stop":
server.destroy();
System.exit(0);
break;
default:
LOGGER.info("Command {} is unknown", data[0]);
}
}
}
这就是最终的解决方案:返璞归真,直接使用最底层的Socket与Java通信。经过实验,速度提升明显,而且由于Socket客户端和服务端可以保持长连接,没有运行一段时间,速度变慢的缺点。
通信主要包含四种情况:
- start:启动Http服务器
- sync:同步内容和位置
- close:关闭预览窗口
- stop:停止Http服务器,退出系统
Java->浏览器
var url = 'ws://127.0.0.1:' + window.location.port + '/ws';
if (!WebSocket) {
console.warn('WebSocket is not support');
} else {
console.log('Try to connect ' + url);
var ws = new WebSocket(url);
ws.onclose = function () {
console.log('Disconnected');
close();
};
ws.onmessage = function (d) {
console.log('Response : ' + d.data.length);
var data = JSON.parse(d.data);
var path = $('#path');
if (path.val() === '') {
init(data);
} else {
if (path.val() === data.path) {
if (data.command === 'close') {
close()
} else if (data.command === 'sync') {
sync(data);
}
}
}
};
}
var init = function (data) {
$('title').html(data.path);
$('#path').val(data.path);
$('.markdown-body').html('');
markdown_refresh(data.units);
highlight_code();
scroll_if_possible();
};
var sync = function (data) {
markdown_refresh(data.units);
highlight_code();
scroll_if_possible();
};
前端就是一个WebSoket客户端,接受两种指令:close和sync,前者用于关闭页面,后者用于同步信息。
大致的流程是浏览器第一次收到服务器消息调用init进行初始化,它会将网页的title和页面元素#path置为文件的路径,将.markdown-body清空,因为浏览器刚启动时会启动一个index介绍页面,需要将其清空,然后调用markdown_refresh刷新显示新的内容,内容显示后hightlight_code负责高亮其中的代码,最后用scroll_if_possible滚动到指定位置。往后浏览器每收到服务器消息都会调用sync同步信息和位置,sync和init内部代码差不多,我就不再赘述了。
Vim->Java
以上走通了Java到浏览器的路,下面看看如何走Vim到Java的路,在整体思路中提到Vim支持Python,所以这条路的主角就是Python,最初是发送Http请求与Java交互,后来又改为使用Socket,原因参看Java服务器那一节。最终的代码如下:
SEP = '\r\n\r\n'
EOF = '$_@'
s = None
def start(port, theme):
global s
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(('127.0.0.1', 23789))
s.send('start' + SEP + str(port) + SEP + theme + EOF)
def sync(path, content, bottom):
s.send('sync' + SEP + path + SEP + base64.b64encode(content) + SEP + str(bottom) + EOF)
def close(path):
s.send('close' + SEP + path + EOF)
def stop():
s.send('stop' + EOF)
s.close()
变量解释:path表示打开文件的路径,content为buffer内容,bottom为当前窗口的末行。
这里的函数和Java Socket服务器那一节里处理的四种情况一一对应,想不起来的可以回去再看下。你可能注意到每次发送消息后面都加了一个EOF,这是因为Tcp是基于流的通信协议,需要一种策略告诉接受方什么时候是一条完整的消息,这里采用的是终结符的形式,即每条消息后面都加了一个EOF告知接收方已经接受了一条完整的消息。另外需要对content进行base64编码,因为content里可能包含一些特殊字符,传输过程中对这些字符处理不一致会导致出错。
下一步就是在Vimscript里调用Python,我就不贴代码了。
一步之遥
至此,插件就基本编写完成了,似乎离成功只有一步之遥了,但成功往往没那么简单。运行一下,乍看起来效果还可以,但是存在两个比较严重的问题:
MathJax抖动
每次滚动时,如果页面里包含MathJax表达式,页面就会一抖一抖的。这是因为所有的内容都存在一个<article></article>标签里,前端每次加载内容,都要刷新内容里所有的MathJax表达式,表达式加载需要时间,未加载完成时有一个空的占位,加载完成使用真正的元素替换,类似网页中的图片加载流程,占位和真正的元素大小不一致,这样给人的感觉就是页面一抖一抖的,最初用的代码如下:
MathJax.Hub.Config({
extensions: ["tex2jax.js"],
jax: ["input/TeX", "output/SVG"],
tex2jax: {
inlineMath: [ ['$','$'], ["\\(","\\)"] ],
displayMath: [ ['$$','$$'], ["\\[","\\]"] ]
},
messageStyle: "none"
});
MathJax.Hub.Queue(["Typeset", MathJax.Hub]);
那怎么解决呢?既然是因为刷新全部的MathJax表达式,那么不让它刷新全部,让它刷新的内容越少抖动不就越小了?查阅MathJax的文档,找到一个函数MathJax.Hub.Queue(['Typeset', MathJax.Hub, element]),它只会刷新页面元素element里的表达式,修改服务器同步信息代码,改全量同步为增量同步,如果里面包含MathJax表达式就调用上述命令刷新。
新的前端代码如下:
$.each(units, function (i, u) {
if (u.operate === 'REPLACE') {
if (u.id === 'toc_container') {
$('.markdown-body').css('padding-left', '200px');
var toc = $('#' + u.id);
toc.html(u.content);
toc.show();
} else {
$('#' + u.id).replaceWith(u.content);
}
} else if (u.operate === 'APPEND') {
$('.markdown-body').append(u.content);
} else if (u.operate === 'REMOVE') {
if (u.id === 'toc_container') {
$('.markdown-body').css('padding-left', '45px');
var cot = $('#' + u.id);
cot.html('');
cot.hide();
} else {
$('#' + u.id).remove();
}
}
if (u.isMathJax === 1) {
MathJax.Hub.Queue(['Typeset', MathJax.Hub, u.id]);
}
})
本地图片不显示
由于浏览器安全策略的限制,页面的img标签不能打开本地图片,即形如<img src='D:\path-to-img.jpg'/>这种写法浏览器不会加载图片,而是提示“Not allowed to load local resource”。一般在文章未发布到网上时,图片地址往往写一个本地的绝对路径,如果不能显示本地图片的话将会大大影响方便性。那么该怎么办呢,第一种方法是写相对路径,即<img src='/path-to-img.jpg'/>,这种方式有很大的局限性,即必须将图片放在一个位置,与网页呈一种相对关系;另一种是写的时候还是写绝对路径,经过程序转成服务器地址,然后通过服务器将图片返给浏览器。显然第二种方式更加灵活,核心代码如下:
private static void transformLocalImgSrc(Element element) {
Elements images = element.select("img");
for (Element img : images) {
String src = img.attr("src");
if (!src.startsWith("http")) {
if (isWindows()) {
img.attr("src", "/image?path=" + src.replace("\\", "\\\\"));
} else {
img.attr("src", "/image?path=" + src);
}
}
}
}
上面的代码将形如D:\path-to-img.jpg的本地路径转成http://127.0.0.1:7788/image?path=D:\\path-to-img.jpg(windows系统,其他系统路径与此略有不同),然后由服务器将图片内容返回。这样就绕过了浏览器的安全策略,实现本地图片的加载了。
阳光总在风雨后
尽管经过了一些风雨,最后还是看到胜利的曙光了。这个项目够小,涵盖的语言和知识并不少,作为一个练手的项目还是不错的,如果碰巧还能给生活提供点便利,何乐而不为呢?想了解大象跳舞的更多细节请戳github。
参考资料:
- Netty in action
- write vim plugin in python