第9章 一致性与共识
一致性保证
分布式一致性与事务隔离级别有相似之处。但总体有着显著区别:事务隔离是为了处理并发执行事务时的各种临界条件,而分布式一致性则主要针对延迟和故障等问题来协调副本之间的状态。
可线性化
所谓线性化,就是让一个系统看起来好像只有一个数据副本,且所有操作都是原子的。可线性化是最强的一致性保证。
例如一个非线性化的体育网站。Alice和Bob坐在同一个房间里各自观看自己的手机,焦集的等待2014年FIFA世界杯决赛的结果。Alice率先看到了比赛结果,然后兴奋地告诉了Bob。结果,Bob刷新之后发现比赛还没有结束。
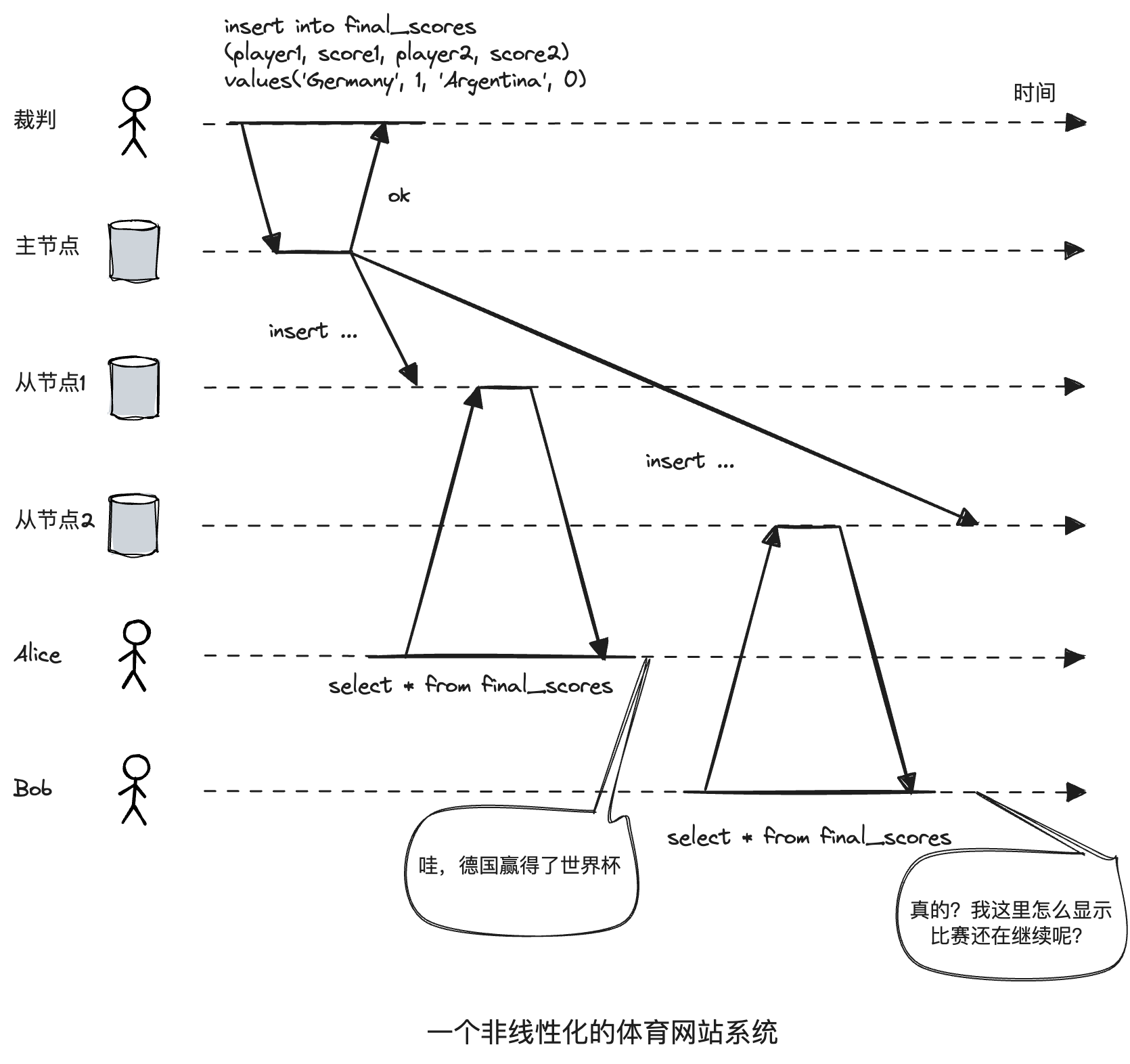
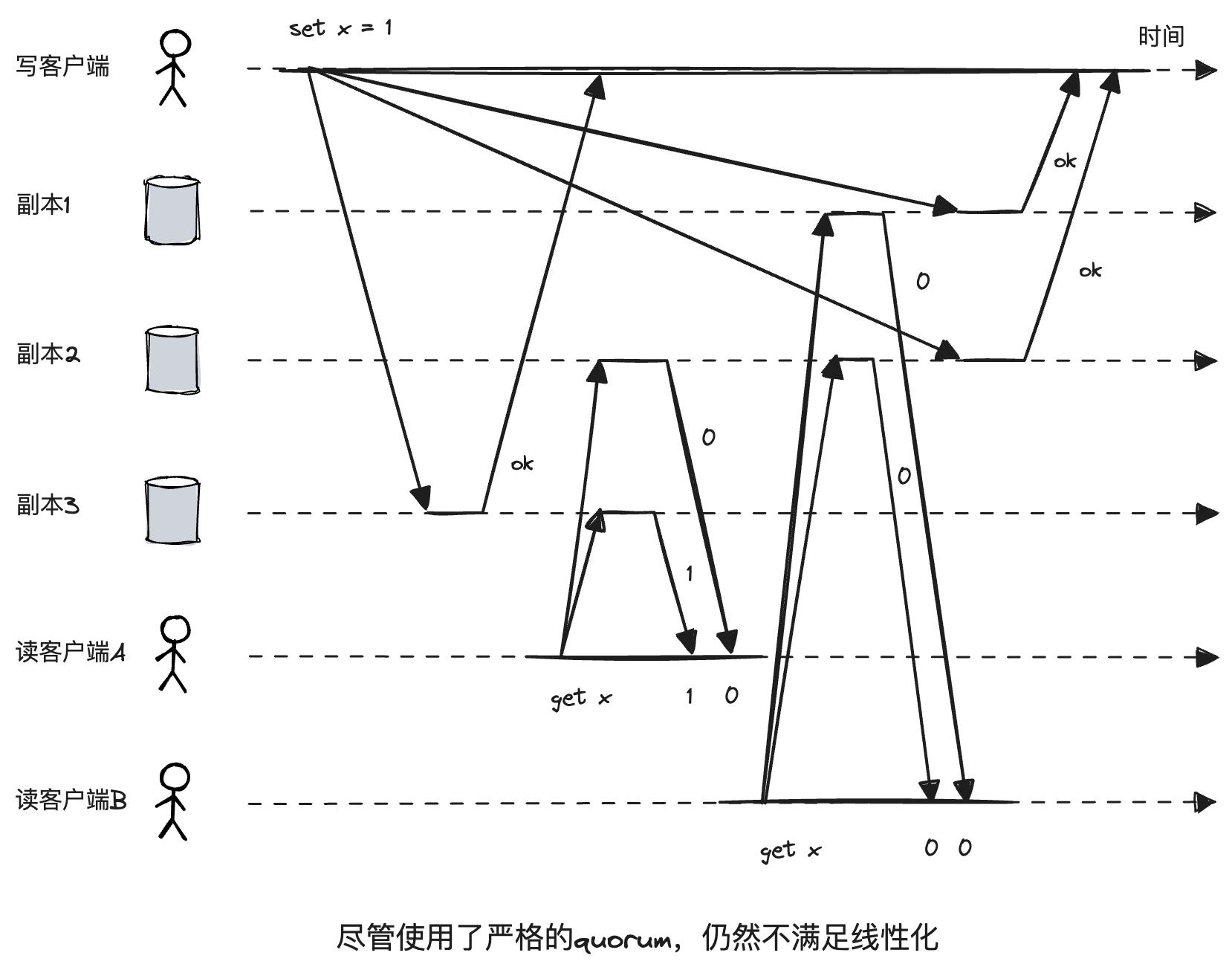
对于Dynamo风格的数据库,即时使用了严格的quorum(法定人数),在网络条件不好的情况下仍然不满足线性化。比如x初始值为0,写客户端向三个副本(n=3,w=3)发送写请求将x更新为1。客户端A在一个节点读到了新值1,客户端B在A读取之后读取,反而收到的都是旧值0。
CAP理论
不仅仅主从复制和多主复制,即使在一个数据中心内部,只要有不可靠的网络,都会发生违背线性化的风险。
CAP理论由Eric Brewer于2000年正式命名,最初是作为一个经验法则被提出,并没有准确的定义,它的含义是“在网络分区的情况下,选择一致性还是可用性”,目的是帮助大家探讨数据库设计的权衡之道,对于具体的系统设计来说意义不大。
- 如果要求线性化,由于网络方面的问题,某些副本断开之后,就必须等待网络修复,或者直接返回错误。无论哪种方式,服务都是不可用。
- 如果不要求线性化,断开连接后,每个副本可以独立处理请求例如写操作(多主复制)。此时服务可用,但结果行为不符合线性化。
可线性化与网络延迟
当前很少有系统真正满足线性化,原因是性能。比如现在多核CPU上的内存:如果某个CPU核上运行的线程修改了一个内存地址,紧接着另一个CPU上的线程尝试读取,则系统无法保证可以读到刚刚写入的值,除非使用了内存屏障或fence指令。
Attiya和Welch证明了如果想要满足线性化,那么读、写请求的响应时间至少与网络中延迟成正比。
顺序保证
顺序与因果关系
如果系统服从因果关系所规定的顺序,称之为因果一致性。
全序关系支持任意两个元素之间进行比较。比如自然数符合全序关系。还有一些元素在某些情况下可以比较,在某些情况下不可比较,称之为偏序。比如集合,当集合有包含关系时,可以比较,否则不可比较。
因果关系并非全序,可线性化强于因果一致性。
序列号排序
虽然因果关系很重要,但是在实际系统中跟踪这种关系却不切实际。在许多系统中,在写入之前会先读取大量的数据,系统无法了解之后的写入是依赖全部读取内容,还是部分。
一个更好的方法:使用序列号或时间戳(可以是逻辑时间戳)。这样所有的操作可以进行全序排序,从而捕获了所有的因果关系,同时强加了比因果关系更为严格的顺序性。
非因果序列发生器
- 每个节点都独立产生自己的一组序列号。比如一个产生奇数,一个产生偶数。
- 物理时钟。
- 给每个节点分配序列号区间范围。比如节点A为0~1000,节点B是1001~2000。
Lamport时间戳
每个节点都有一个唯一的标识符,且每个节点都有有一个计数器记录请求总数。它的形式是一个键值对:(计数器,节点ID)。可以解决上面三种序列号都可能与因果不一致的情况。
假设事件A和事件B的计数器为C(A)和C(B),那么如果A在B之前发生,那么必有C(A) < C(B),反过来,如果C(A) < C(B),A并不一定发生在B之前。也就是说,时间戳与因果关系是必要不充分的。注意这里说的A发生在B之前是在说因果关系,来自于happen-before的直译,并不是现实中物理时间上发生的意义。
比如下面图中节点1事件(1, 1)小于节点2的事件(2, 2),但是二者并没有因果关系,而是一种并行关系。
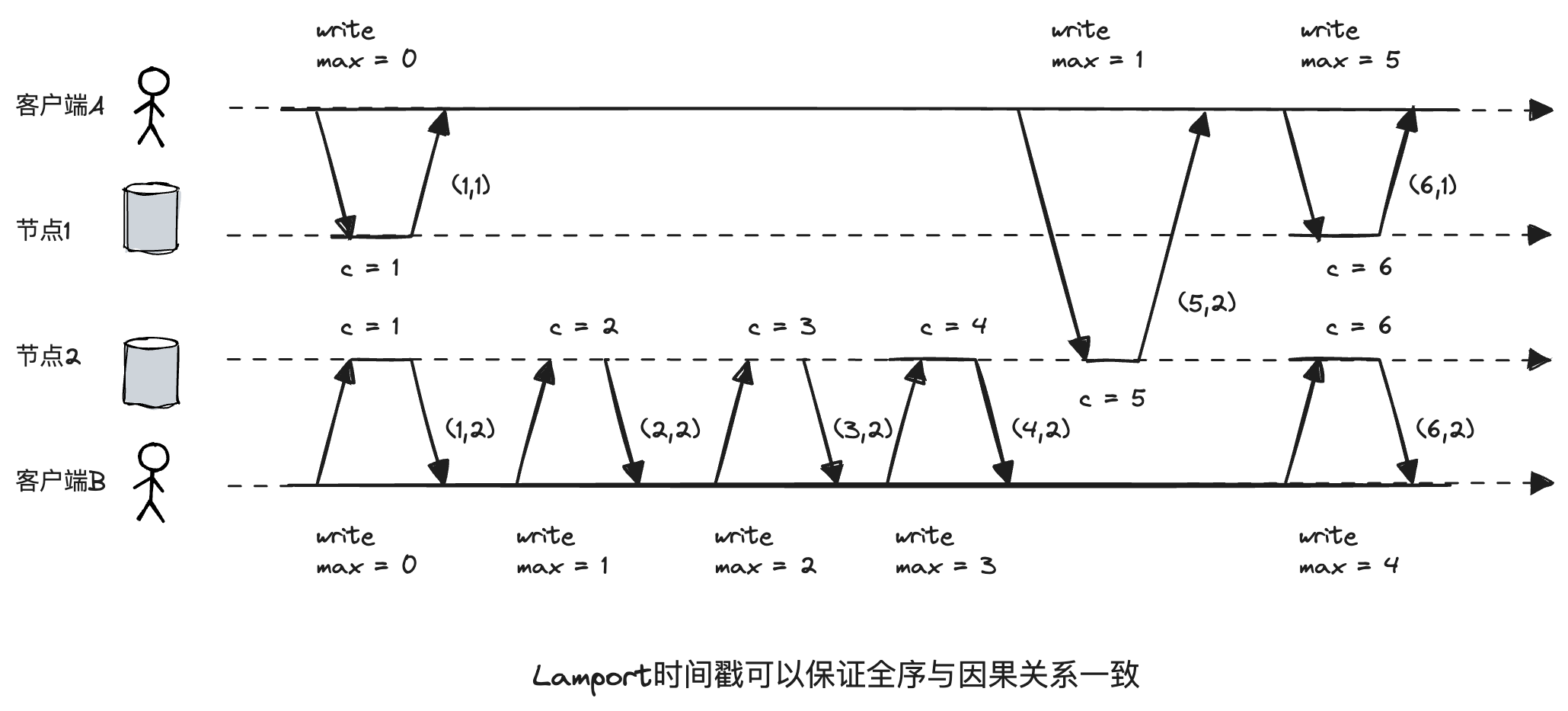
如果C(A) = C(B),A和B是什么关系呢?答案是并行关系。比如上面的(1, 1)和(1, 2)、(6, 1)和(6, 2)。
也就是说,Lamport时间戳使得所有的事件都能比较,即全序,包括那些并行的事件,以及具有因果关系的事件。这样的结果是因果关系的事件先后顺序确实都没问题,但是并行事件实际发生顺序可能是错的。比如节点1事件(1, 1)的lamport时间戳小于节点2的事件(2, 2),但是在物理时间上,后者可能先于前者发生。
时间戳排序依然不够
为了实现用户名唯一性约束这样的目标,仅仅对操作进行全序排列还是不够的,还需要知道这些操作是否发生、发生时间等。因为操作是分布式的,在当前节点用户名创建的这一瞬间,你需要收集到在其他节点上是否有其他请求也在创建同一个用户。
要想知道什么时候全序关系已经确定就需要“全序关系广播”。
全序关系广播
全序关系广播常指节点之间交换消息的某种协议。它要求满足两个基本安全属性:
- 可靠发送:没有消息丢失,如果消息发送到了某一个节点,则它一定要发送到所有节点。
- 严格有序:消息总是以相同的顺序发送到每个节点。
像ZooKeeper和etcd这样的共识服务实际上就实现了全关系序广播。
采用全序关系广播实现线性化存储
全序关系与线性化并不等同,但是关系密切。全序广播是异步的,保证以固定的顺序可靠的传递,但不能保证何时传递。相反,线性化是一种最近的保证,读取保证看到最新写入的值。
理解全序关系广播的一种方式是将其看作日志。传递消息就像追加方式更新日志。以全序关系广播以追加日志的方式来实现原子比较-设置操作(创建用户):
- 在日志中追加一条消息,并指明想要的用户名。
- 读取日志,将其广播给所有节点,并等待回复。
- 检查是否有任何消息生成用户名已被占用。如果是中止操作,否则成功获得该用户名。
此过程实现了线性化写入,却无法保证线性化读取,即读取时可能是旧值。具体来说,这里只提供了顺序一致性,也称为时间一致性,弱于线性化保证。为了同时满足线性化读取,有以下几个方案:
- 可以采用追加的方式将读请求排序、广播,然后各个节点获取该日志,当本节点收到消息时才执行真正的读操作。消息在日志中的位置已经决定了读取发生的时间点。etcd的quorum读取和这个思路相似。
- 如果日志允许你以线性化的方式获取最新日志的位置,则查询该位置,等待直到该位置之前的所有条目都已经发送给你,接下来再执行读取。这与ZooKeeper的sync()操作思路相同。
- 可以从同步更新的副本上进行读取,这样确保总是读到最新值。这种技术可以用于链式复制。
(没看懂前面两点的不同)
采用线性化存储实现全序关系广播
也可以反过来,通过线性化实现全序广播。
最简单的方法是假设有一个线性化的寄存器来存储一个计数,然后使其支持原子自增-读取操作或者原子比较设置操作。
与Lamport时间戳不同,线性寄存器的数字不会存在间隙,因此如果节点完成了消息4的发送,且接收了序列6的消息,那么它对消息6回复之前必须等待消息5。Lamport时间戳规则不是这样,这是区别全序关系广播与时间戳排序的关键。
如果不存在失效,实现线性寄存器不难,否则就等同于分布式共识算法。可以证明,线性化存储、全序广播、分布式共识三者是等价的。
分布式事务与共识
2PC
两阶段提交(two-phase commit,2PC)是一种在多节点之间实现事务原子提交的算法,用来确保所有节点要么全部提交,要么全部中止。2PC在某些数据库内部使用,或者以XA事务形式(例如Java Transaction API)或SOAP Web服务WS-AtomicTransaction的形式提供给应用程序。
2PC在分布式数据库中负责原子提交,2PL提供可串行化的隔离。
2PC引入了一个角色:协调者(也称事务管理器),普通节点称为参与者。常见的协调者包括Narayana,JOTM,BTM或MSDTC。
2PC包括两个阶段:
- 阶段1:协调者询问所有参与者是否准备好?如果都回答“是”则进入阶段2,否则中止。
- 阶段2:协调者向所有参与者发送提交请求。如果有参与者超时或失败,协调者会一直重试,直到成功为止。
更详细的步骤:
- 当应用程序启动一个分布式事务时,首先向协调者请求事务ID。该ID是全局唯一的。
- 应用程序在每个节点上执行单结点事务,并将全局唯一事务ID附加到事务上。如果这个阶段出现问题,协调者和其他参与者都可以安全中止。
- 当应用程序准备提交时,协调者向所有参与者发送准备请求。如果任何一个参与者失败或超时,协调者通知所有参与者放弃事务。
- 参与者收到准备请求后,确保在任何情况下都可以提交事务(包括系统崩溃,电源故障或磁盘空间不足),包括安全地将事务数据写入磁盘,并检查是否存在冲突或约束违规。
- 如果所有参与者都返回是,那么协调者将发送提交请求,并将决定写入磁盘的事务日志中。这个时刻称为提交点。
- 协调者发送提交请求。如果有参与者超时或失效,协调者将会一直重试,直到成功。
类比结婚的例子,神父要问双方是否愿意嫁(娶)给对方,双方都回答“是”,神父才会宣布双方结为夫妻。并且,一旦说出“我愿意”就没有反悔的余地,即使之后马上晕倒了。
如果在参与者发送了准备好的回复后,协调者如果崩溃,参与者只能等待。因此2PC也被称为阻塞式原子提交协议。
实践中的分布式事务
分布式事务有严重的性能问题。例如,MySQL的分布式事务比单结点事务慢10倍以上。2PC性能下降的主要原因是事务日志以及额外的网络往返开销。
两类分布式事务:
- 数据库内部:VoltDB和MySQL Cluster的NDB存储引擎就支持这样的内部分布式事务。
- 异构:存在两种或两种以上的不同的参与者实现技术。
后者更具挑战。
XA交易
X/Open XA(eXtended Architecture,XA)是异构环境下实施两阶段提交的一个工业标准,1991推出。目前许多传统关系数据库(包括PostgreSQL、MySQL、DB2、SQL Server和Oracle)和消息队列(包括ActiveMQ、HornetQ、MSMQ和IBM MQ)都支持XA。
XA不是一个网络协议,而是一个与事务协调者进行通信的C API。也有其他语言的绑定,比如JTA(Java Transaction API),JTA支持非常多的JDBC(Java Database Connectivity)和消息队列驱动(JMS)。
当参与者失效或协调者崩溃时,分布式事务陷入停顿,因为参与者有可能持有锁,比如数据库事务通常持有行级独占锁。可串行化隔离中两阶段锁的数据库还对曾经读取的行持有读-共享锁。参与者或协调者恢复可能也有意外发生,比如参与者重启也不会放弃锁(2PC正确实现要求),协调者丢失事务日志,这个时候就需要人工介入。
支持容错的共识
共识问题的形式化描述:一个或多个节点可以提议某些值,由共识算法来决定最终值。共识算法必须满足以下性质:
-
协商一致性(Uniform agreement)
所有节点都接受相同的决议。
-
诚实性(Integrity)
所有节点不能反悔,即对一项提议不能有两次决定。
-
合法性(Validity)
如果决定了值v,则v一定是某个节点提议的。
-
可终止性(Termination)
节点如果不崩溃则最终一定可以达成决议。
协商一致性和诚实性定义了共识的核心思想:决定一经做出,就不能改变。有效性排除了一些无意义的方案。可终止性引入了容错的思想。它强调一个共识算法要有所作为,不能空转。可终止性是一种活性,其他三个特性是安全性。
可终止性的前提是发生崩溃或不可用的节点必须小于半数节点。
大多数共识算法都假定不存在拜占庭式错误。但是研究表明,只要发生拜占庭式故障的节点少于三分之一,也可以达成共识。
共识算法与全序广播
最著名的共识算法有VSR、Paxos、Raft和ZAB。这些算法其实并没有直接使用上面的形式化模型(四大属性)。相反,它们定义了一系列值,然后采用全序关系广播算法,这样更加高效。
全序广播的要点是,消息按照相同的顺序到达所有节点,有且只有一次(不丢失,不重复)。相当于多轮共识:在每一轮,节点提出它们接下来想要发送的消息,然后决定下一个消息的全局顺序。
- 由于协商一致性,所有节点决定以相同的顺序发送相同的消息(只是发送吗?)。
- 由于诚实性,消息不能重复。
- 由于合法性,消息不会被破坏,也不是凭空捏造。
- 由于可终止性,消息不会丢失。
VSR、Raft和Zab都直接采取了全序关系广播,这比重复性的一轮共识只解决一个提议更高效。
Epoch和Quorum
问题是想要达成决议,必须先有主节点,想要主节点得让所有节点达成某种共识,看起来这是一个死循环。解决之道就是本节的内容。
协议定义了一个世代编号(epoch number),对应于Paxos中的ballot number,VSP中的view number,以及Raft中的term number,并保证在每个世代中,主节点是唯一的。
两轮投票:第一轮决定谁是主节点,第二轮对主节点的决议进行投票。关键一点,参与两轮的quorum(法定人数)必须有重叠。这样可以确保:没有发生更高epoch的主节点选举,当前的主节点地位没有改变,可以安全地就提议进行投票。
投票过程看起来很像2PC。区别在于,2PC协调者不是靠选举产生;容错共识算法只需要收集大部分节点的投票即可通过决议,而不像2PC收集全部的投票。
成员与协调服务
ZooKeeper和etcd被称为“分布式键值存储”或“协调与配置服务”。大多数情况下,可能不会直接使用这些服务,而是在中间件中间接的使用。功能包括:
- 线性化原子操作:实现分布式锁。
- 操作全序:对每个操作都赋予一个事务ID(zxid)和版本号(cversion)。
- 故障检测:临时节点配合心跳检测。
- 更改通知:节点数据变化可以发送通知。
适用的场景:
-
节点任务分配
如果系统有多个实例,需要一个充当主节点。当主节点失效时,由其他节点来接管。或者分区动态增删,决定哪些分区分配给哪些节点。都可以使用ZK的临时节点和通知机制实现。
-
服务发现
例如,需要某项服务时,应该连接哪些ip等。传统上,通过服务名称获取IP地址使用DNS,它使用多层缓存实现高性能与高可用性,但是不满足线性化。
-
成员服务
用于确定哪些节点处于活动状态并属于集群的有效成员。